
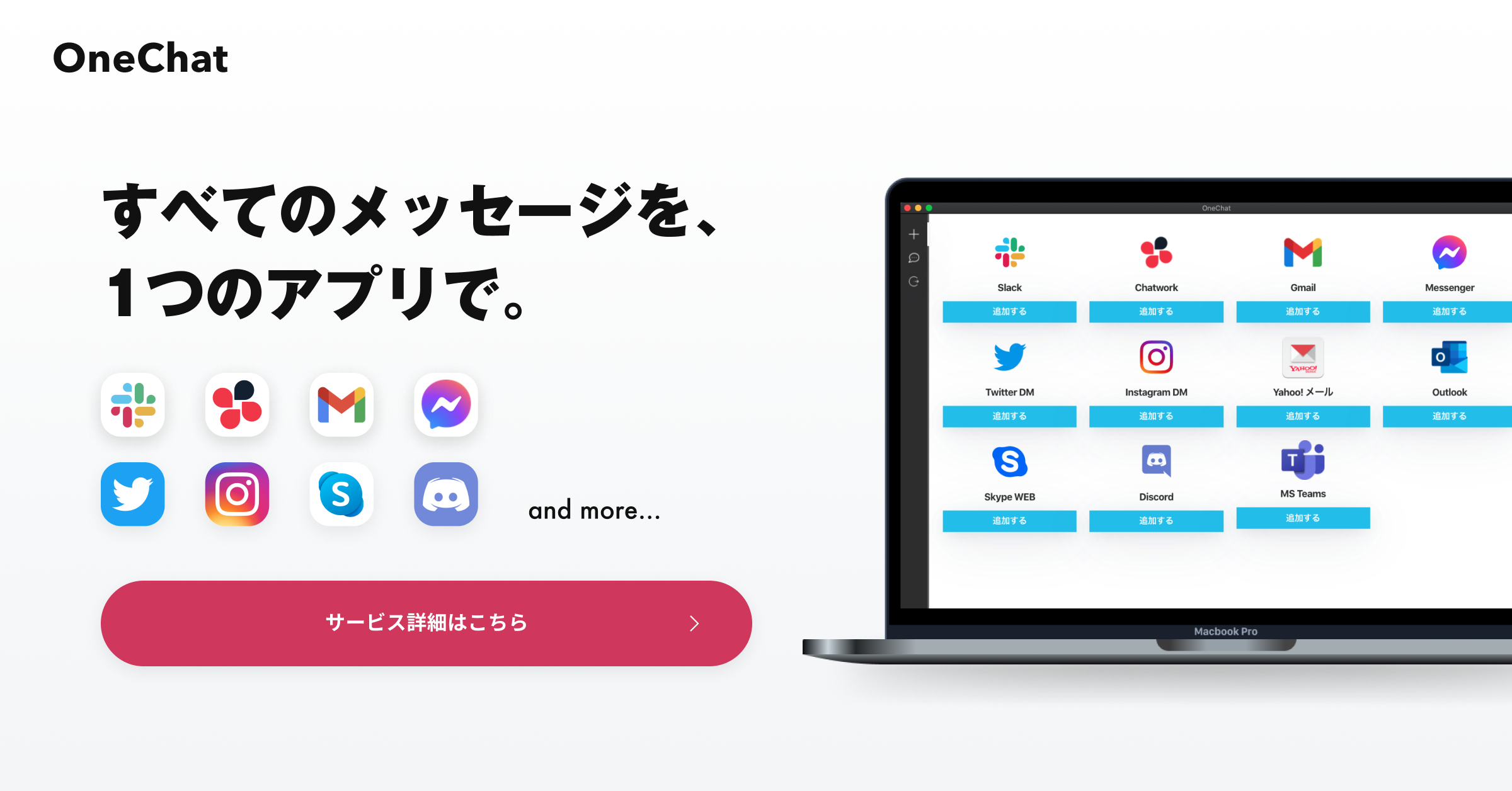
ExcelのDISTINCT関数は、データセットより重複している値を取り除き、一意の値のみを抽出する強力なツールです。また、初心者でも簡単に用いることができる関数であり、データの分析や整理において役に立ちます。
本記事では、DISTINCT関数の基本概念から実際の使用例、他の関数との組み合わせ方法まで、幅広く紹介します。
DISTINCT関数とは?

DISTINCT関数とはどのような関数なのかについてみていきましょう。
DISTINCT関数の基本概念
DISTINCT関数は、Excelにおいてデータセットから重複する値を取り除き、一意の値のリストを抽出することができる関数です。この関数は、膨大に存在するデータの中から一位の項目の抽出を行いたい際や、重複するデータの削除を行い、データセットの整理をしたい場合に有用な関数です。
DISTINCT関数と他の重複除去方法の比較
Excelには、DISTINCT関数の他にも重複データの除去方法が用意されています。以下では、DISTINCT関数と他の重複除去方法の比較をして、メリットとデメリットを見ていきましょう。
①DISTINCT関数
メリット
- データ変更が行われると、自動的に一意の値のリストが更新される
- 短いコードを用いて重複の除去が可能
- 他の関数との組み合わせで、複雑なデータを処理できる
デメリット
- 利用可能バージョンに制限がある(Excel 2019以降、またはOffice 365)
- 適用範囲が単一の列や範囲のみである
②「重複の削除」機能
Excelの「データ」タブ内にある「重複の削除」機能を用いることで、重複データを削除することができます。
メリット
- GUI操作により直感的に機能を用いることができ、設定も簡単に行える
- 複数の列やデータセットの操作を一度に行うことができる
デメリット
- 一度実行されると結果は固定となり、テータに変更が加えられた場合は再操作を必要とする
- 関数やスクリプトのように自動化されていないため、手動で機能を使用する必要がある
③「フィルター」機能
Excelの「データ」タブ内にある「フィルター」機能を用いて重複データが表示されないように設定することができます。
メリット
- 「フィルター」機能のオプションから「重複しない」フィルターを選択するだけで適用できる
- 設定後すぐに結果が反映される
デメリット
- 元データに変更が加えられた場合、フィルターを再適用する必要がある
- フィルターにより隠されたデータは、表示されていないだけでExcel上に存在しているため、重複を完全に除去することができない
④ピボットテーブル
ピボットテーブルを用いてデータの集計を行い、一意の値を抽出することができます。
メリット
- データの集計や分析を容易に行うことができる
- カスタマイズが豊富なため、多様な集計方法や表示形式を選べる
デメリット
- ピボットテーブルの設定は複雑なため、ある程度の知識や習熟を要する
- データに変更が加えられた場合に自動で更新するためには、手動のリフレッシュや追加の設定をする必要がある
DISTINCT関数の基本的な使い方
DISTINCT関数の基本的な使い方についてみていきましょう。
DISTINCT関数の基本構文
DISTINCT関数の基本構文は次の通りです。
=DISTINCT(配列)
| 引数 | 概要 |
| 配列 | 重複を除去したいデータ範囲を指定します。ここにはセル範囲やテーブル、配列定数を入力します。 |
実際の使用例
DISTINCT関数の実際の使用例についてみていきましょう。
①基本的な一意の値の抽出
例:下記の社員名のリストより、重複している名前を除去した社員名のリストを作成する
| 行\列 | A |
| 1 | 社員名 |
| 2 | 高橋 健 |
| 3 | 田中 美咲 |
| 4 | 鈴木 一郎 |
| 5 | 田中 美咲 |
| 6 | 高橋 健 |
| 7 | 伊藤 玲奈 |
この場合の数式は次の通りです。
=DISTINCT(A:A)
この数式の結果は次の通りです。
| 行\列 | A |
| 1 | 社員名 |
| 2 | 高橋 健 |
| 3 | 田中 美咲 |
| 4 | 鈴木 一郎 |
| 5 | 伊藤 玲奈 |
②一意の値を複数列の配列から抽出
例:複数列にわたるデータより一意の値のリストを抽出する
| 行\列 | A | B |
| 1 | 社員番号 | 社員名 |
| 2 | 14321 | 高橋 健 |
| 3 | 15234 | 田中 美咲 |
| 4 | 16578 | 鈴木 一郎 |
| 5 | 15234 | 田中 美咲 |
| 6 | 14321 | 高橋 健 |
| 7 | 17890 | 伊藤 玲奈 |
この場合の数式は次の通りです。
=DISTINCT(A:B)
この数式の結果は次の通りです。
| 行\列 | A | B |
| 1 | 社員番号 | 社員名 |
| 2 | 14321 | 高橋 健 |
| 3 | 15234 | 田中 美咲 |
| 4 | 16578 | 鈴木 一郎 |
| 5 | 17890 | 伊藤 玲奈 |
DISTINCT関数の応用例
DISTINCT関数の応用例についてみていきましょう。
より複雑なデータセットでの使用例
DISTINCT関数は単純なデータセットのみだけでなく、より複雑なデータセットにおいても有用です。以下では、より複雑なデータセットにおけるDISTINCT関数の使用例について紹介します。
例:複雑な列から一意の値の組み合わせを抽出する
| 行\列 | A | B |
| 1 | 製品名 | 販売地域 |
| 2 | Apple | North |
| 3 | Banana | South |
| 4 | Apple | North |
| 5 | Cherry | East |
| 6 | Banana | West |
| 7 | Cherry | East |
| 8 | Apple | South |
商品データが製品名や販売地域などの複数列に分かれている場合に、その一意の値の組み合わせの抽出をDISTINCT関数を用いて行うことができます。この場合の数式は次の通りです。
=DISTINCT(A:B)
この数式の結果は次の通りです。
| 行\列 | A | B |
| 1 | 製品名 | 販売地域 |
| 2 | Apple | North |
| 3 | Banana | South |
| 4 | Cherry | East |
| 5 | Banana | West |
| 6 | Apple | South |
この例では、製品名と販売地域の組み合わせで一意の値が入力されている行の抽出を行なっています。
DISTINCT関数と他の関数との組み合わせ
DISTINCT関数と他の関数を組み合わせることで、データのフィルタリングや解析、要約などを効率的に行うことができます。以下では、DISTINCT関数と他の関数を組み合わせた使用例について紹介します。
①DISTINCT関数とCOUNT関数の組み合わせ
一意の値をカウントすることができます。
例:学生の出席記録より一意の学生数をカウントする
| 行\列 | A |
| 1 | 学籍番号 |
| 2 | 14321 |
| 3 | 15234 |
| 4 | 16578 |
| 5 | 14321 |
| 6 | 17890 |
| 7 | 15234 |
上記データより、一意の学生数のカウントをDISTINCT関数とCOUNT関数を組み合わせることで行います。その場合の数式は次の通りです。
=COUNT(DISTINCT(A:A))
②DISTINCT関数とFILTER関数の組み合わせ
一意の値を抽出して、抽出した値に基づいてデータのフィルタリングをすることができます。
例:商品リストより一意の商品を抽出・フィルタリングする
| 行\列 | A | B | C |
| 1 | 製品名 | カテゴリ | 価格 |
| 2 | フライパン | キッチン用品 | 800 |
| 3 | シャンプー | バス用品 | 700 |
| 4 | フライパン | キッチン用品 | 1200 |
| 5 | トイレットペーパー | トイレ用品 | 500 |
| 6 | シャンプー | バス用品 | 780 |
入力されているカテゴリから一意の値を抽出し、商品リストのフィルタリングをする場合は、次のような数式となります。
=FILTER(A:C, B:B = DISTINCT(B:B))
③DISTINCT関数とINDEX関数、MATCH関数の組み合わせ
一意の値をもとに、データの検索をすることができます。
例:顧客リストより一意の顧客IDを用いて顧客名の検索をする
| 行\列 | A | B |
| 1 | 顧客ID | 顧客名 |
| 2 | 14321 | 高橋 健 |
| 3 | 15234 | 田中 美咲 |
| 4 | 16578 | 鈴木 一郎 |
| 5 | 15234 | 田中 美咲 |
| 6 | 14321 | 高橋 健 |
| 7 | 17890 | 伊藤 玲奈 |
顧客リストから一意の顧客IDを用いて顧客名の取得を行う場合は、次のような数式となります。
=INDEX(B:B, MATCH(DISTINCT(A:A), A:A, 0))
参考:
よくある質問
DISTINCT関数に関連するよくある質問について紹介します。
他の重複除去方法との違いは?
DISTINCT関数と他の重複除去方法にはいくつかの違いがあります。それぞれの方法のメリットとデメリットについてみていきましょう。
①DISTINCT関数
メリット
- データ変更が行われると、自動的に一意の値のリストが更新される
- 短いコードを用いて重複の除去が可能
- 他の関数との組み合わせで、複雑なデータを処理できる
デメリット
- 利用可能バージョンに制限がある(Excel 2019以降、またはOffice 365)
- 適用範囲が単一の列や範囲のみである
②「重複の削除」機能
Excelの「データ」タブ内にある「重複の削除」機能を用いることで、重複データを削除することができます。
メリット
- GUI操作により直感的に機能を用いることができ、設定も簡単に行える
- 複数の列やデータセットの操作を一度に行うことができる
デメリット
- 一度実行されると結果は固定となり、テータに変更が加えられた場合は再操作を必要とする
- 関数やスクリプトのように自動化されていないため、手動で機能を使用する必要がある
③「フィルター」機能
Excelの「データ」タブ内にある「フィルター」機能を用いて重複データが表示されないように設定することができます。
メリット
- 「フィルター」機能のオプションから「重複しない」フィルターを選択するだけで適用できる
- 設定後すぐに結果が反映される
デメリット
- 元データに変更が加えられた場合、フィルターを再適用する必要がある
- フィルターにより隠されたデータは、表示されていないだけでExcel上に存在しているため、重複を完全に除去することができない
④ピボットテーブル
ピボットテーブルを用いてデータの集計を行い、一意の値を抽出することができます。
メリット
- データの集計や分析を容易に行うことができる
- カスタマイズが豊富なため、多様な集計方法や表示形式を選べる
デメリット
- ピボットテーブルの設定は複雑なため、ある程度の知識や習熟を要する
- データに変更が加えられた場合に自動で更新するためには、手動のリフレッシュや追加の設定をする必要がある
DISTINCT関数の限界と注意点は?
DISTINCT関数にはいくつかの限界と注意点があります。それぞれについて紹介します。
| 限界(制限) | 詳細 |
| 利用可能バージョン | DISTINCT関数は、利用可能なExcelバージョンに制限があります。(Excel 2019以降、またはOffice 365) |
| 機能制限 | DISTINCT関数は、一意の値を抽出するために用いられるシンプルな構成の関数ですが、シンプルであるがためにDISTINCT関数単体でのデータ集計や分析といった複雑なデータ処理が求められる作業には不向きです。 |
| 互換性 | DISTINCT関数が用いられたワークブックの共有を行う場合、共有相手のExcelバージョンがDISTINCT関数に対応していない場合は正しく関数が動作しない場合があります。 |
| 注意点 | 詳細 |
| データの選択範囲 | 適切に範囲選択を実行しないと意図しない結果が返ってくることがあります。常に範囲をチェックし、必要に応じて調整しましょう。 |
| 空白セルの扱い | DISTINCT関数においては、空白セルも一意の値として扱われます。そのため空白セルを除外したい場合は、FILTER関数などの関数と組み合わせて用いましょう。 |
| データ型の一致 | 数値や文字列といった異なるデータ型が混在している場合は、意図した結果が返されない場合があります。そのためデータ型を一致させるか、混在させないようにしましょう。 |
| パフォーマンス | DISTINCT関数を大規模データセットに対して適用する場合、パフォーマンスが落ちてしまうことがあります。特に、行や列が多く含まれる場合は計算時間が長くかかる可能性があります。 |
Excelで重複しないリストを作るには?
Excelで重複しないリストを作成したい場合は、DISTINCT関数を用いると良いでしょう。以下で簡単な例を用いたDISTINCT関数の使用方法について解説します。
①基本的な一意の値の抽出
例:下記の社員名のリストより、重複している名前を除去した社員名のリストを作成する
| 行\列 | A |
| 1 | 社員名 |
| 2 | 高橋 健 |
| 3 | 田中 美咲 |
| 4 | 鈴木 一郎 |
| 5 | 田中 美咲 |
| 6 | 高橋 健 |
| 7 | 伊藤 玲奈 |
この場合の数式は次の通りです。
=DISTINCT(A:A)
この数式の結果は次の通りです。
| 行\列 | A |
| 1 | 社員名 |
| 2 | 高橋 健 |
| 3 | 田中 美咲 |
| 4 | 鈴木 一郎 |
| 5 | 伊藤 玲奈 |
②一意の値を複数列の配列から抽出
例:複数列にわたるデータより一意の値のリストを抽出する
| 行\列 | A | B |
| 1 | 社員番号 | 社員名 |
| 2 | 14321 | 高橋 健 |
| 3 | 15234 | 田中 美咲 |
| 4 | 16578 | 鈴木 一郎 |
| 5 | 15234 | 田中 美咲 |
| 6 | 14321 | 高橋 健 |
| 7 | 17890 | 伊藤 玲奈 |
この場合の数式は次の通りです。
=DISTINCT(A:B)
この数式の結果は次の通りです。
| 行\列 | A | B |
| 1 | 社員番号 | 社員名 |
| 2 | 14321 | 高橋 健 |
| 3 | 15234 | 田中 美咲 |
| 4 | 16578 | 鈴木 一郎 |
| 5 | 17890 | 伊藤 玲奈 |
まとめ
DISTINCT関数は、データセットから重複を取り除いて、一意の値のみを取得したい場合に便利な関数です。その基本概念や使い方を理解して、他の重複を取り除く手段との違いを理解することによりより効果的なデータ処理を実現することができます。
Excel DISTINCT関数に関する重要用語
| 用語 | 説明 |
| DISTINCT | =DISTINCT(配列)データセットから重複する値を取り除き、一意の値のリストを抽出することができる |
| COUNT | =COUNT(値 1, [値 2], …)数値を含むセルの個数や引数リストに含まれている数値の個数をカウントすることができる |
| FILTER | =FILTER(配列,含む,[空の場合])設定した条件に基づいて、選択した配列やセル範囲からデータを抽出することができる |
| INDEX | =INDEX(配列, 行番号, [列番号])設定した範囲から、指定した行と列に該当するセルに入力されている値を取り出すことができる |
| MATCH | =MATCH(検査値, 検査範囲, [照合の型])設定した検索範囲において指定した検査値が何番目のセルに入力されているかを求めることができる |
